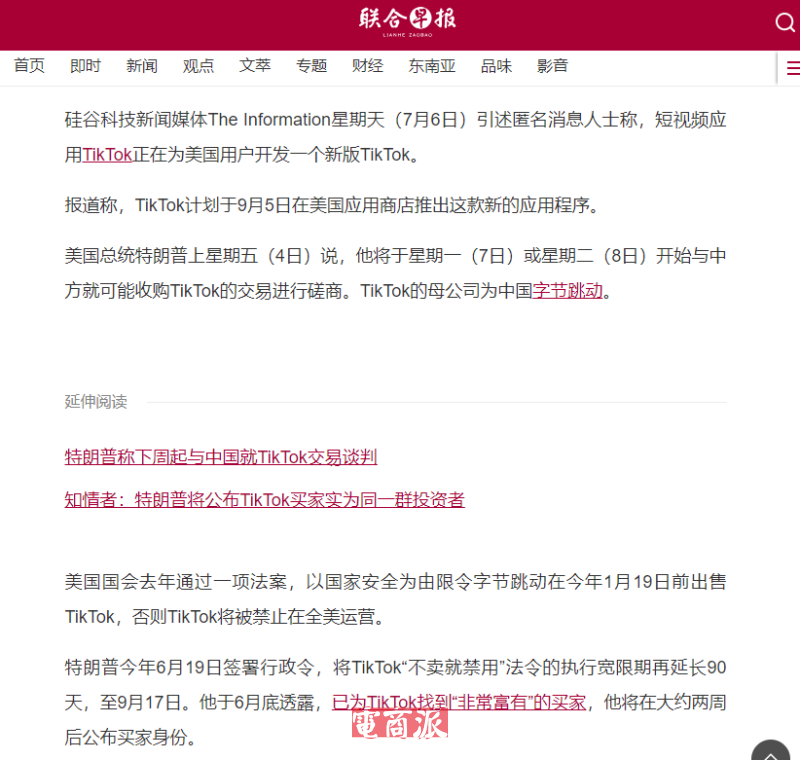
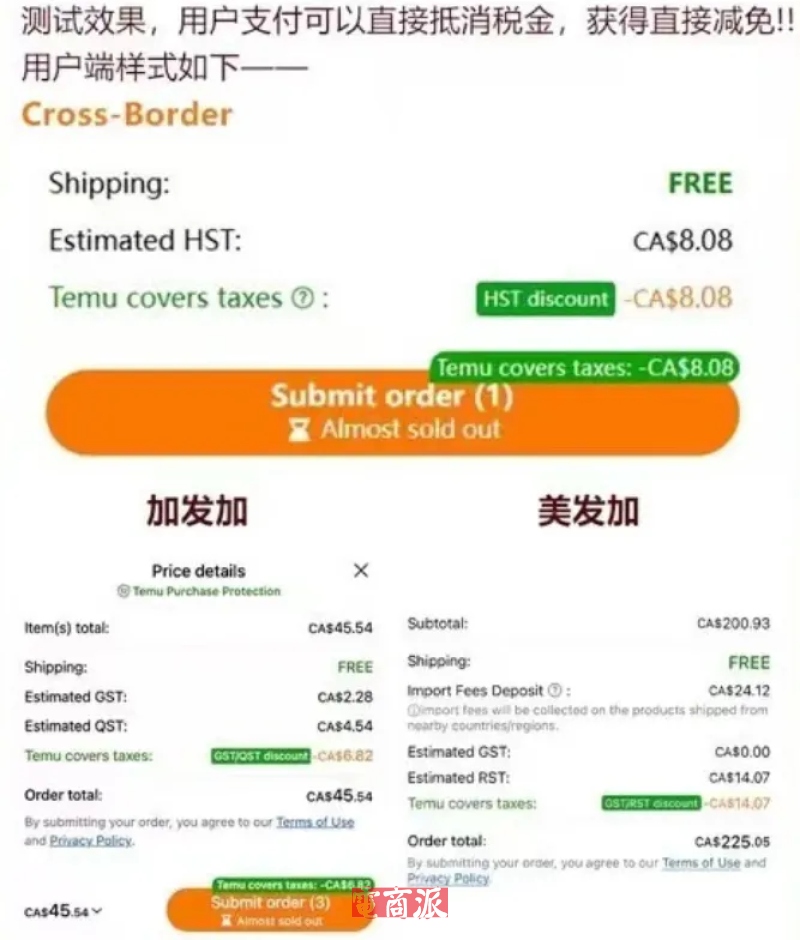
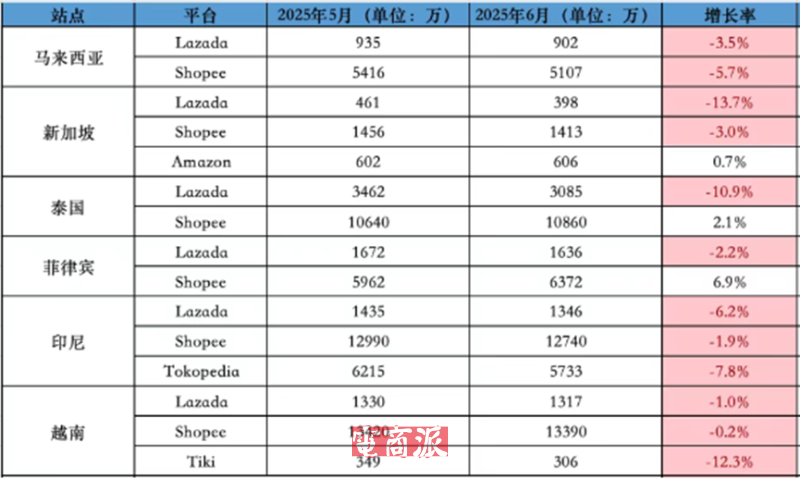
邮件群发-邮件群发软件|邮件批量发送工具|群发邮件平台|批量邮箱发送系统公司
邮件群发-邮件群发软件|邮件批量发送工具|群发邮件平台|批量邮箱发送系统公司网页数据抓取工具

网页数据抓取工具是一种用于提取网页上的数据的软件工具,它可以自动化地从网页上收集所需的信息,并将其保存到本地计算机或数据库中。这种工具通常通过网络协议(例如HTTP或HTTPS)访问网页,并解析HTML或其他标记语言来提取所需的信息。网页数据抓取工具广泛应用于各种领域,包括网络搜索、数据挖掘、竞争情报、市场研究等。
网页数据抓取工具的核心功能是自动化抓取网页并提取所需的数据。一般而言,它主要包括以下几个步骤:
1. 发送请求:网页数据抓取工具首先根据用户指定的URL发起HTTP或HTTPS请求,请求目标网页的内容。
2. 获取响应:一旦服务器收到了请求,它将返回一个HTTP响应,网页数据抓取工具需要获取并解析这个响应。
3. 解析HTML:网页数据抓取工具会解析HTML响应,提取其中的数据。它可以使用各种HTML解析库,例如BeautifulSoup、Scrapy等。
4. 提取数据:一旦HTML响应解析完成,网页数据抓取工具将根据用户的要求提取数据。它可以使用XPath、正则表达式或其他规则来定位和提取需要的数据。
5. 保存数据:*,网页数据抓取工具将提取的数据保存到本地计算机或数据库中。它可以将数据保存为文本文件、CSV文件、JSON文件等格式,以供进一步处理和分析。
除了基本功能外,网页数据抓取工具通常还具有以下特点:
1. 多线程处理:为了提高效率,网页数据抓取工具可以使用多线程或异步方式发送请求和处理响应。这样可以并发处理多个请求,减少响应时间。
2. 代理支持:为了应对反爬虫机制和IP封禁,网页数据抓取工具通常支持使用代理服务器发送请求。这样可以隐藏真实的IP地址,增加抓取的稳定性和可靠性。
3. 用户代理设置:为了模拟真实用户的行为,网页数据抓取工具可以设置自定义的用户代理字符串。这样可以伪装为不同的浏览器或设备,减少被网站识别为爬虫的概率。
4. 反爬虫处理:为了应对网站的反爬虫机制,网页数据抓取工具通常具有一些反爬虫处理能力。例如,它可以自动处理验证码、登陆验证等问题。
5. 配置灵活:网页数据抓取工具通常具有灵活的配置选项,可以根据用户的需求进行定制。用户可以指定抓取的深度、频率、数据格式等,以获得满足自己需求的数据。
网页数据抓取工具的应用非常广泛。在搜索引擎领域,它们被用于构建搜索引擎的索引,提供网页内容的检索。在数据挖掘和竞争情报中,它们被用于获取竞争对手的产品信息、价格信息等。在市场研究中,它们被用于收集消费者评论、社交媒体数据等。
总之,网页数据抓取工具是一种强大的软件工具,可以自动化地从网页上提取所需的数据。它通过发送请求、获取响应、解析HTML、提取数据和保存数据等步骤实现这一功能。网页数据抓取工具具有多线程处理、代理支持、用户代理设置、反爬虫处理、灵活的配置等特点,应用非常广泛。