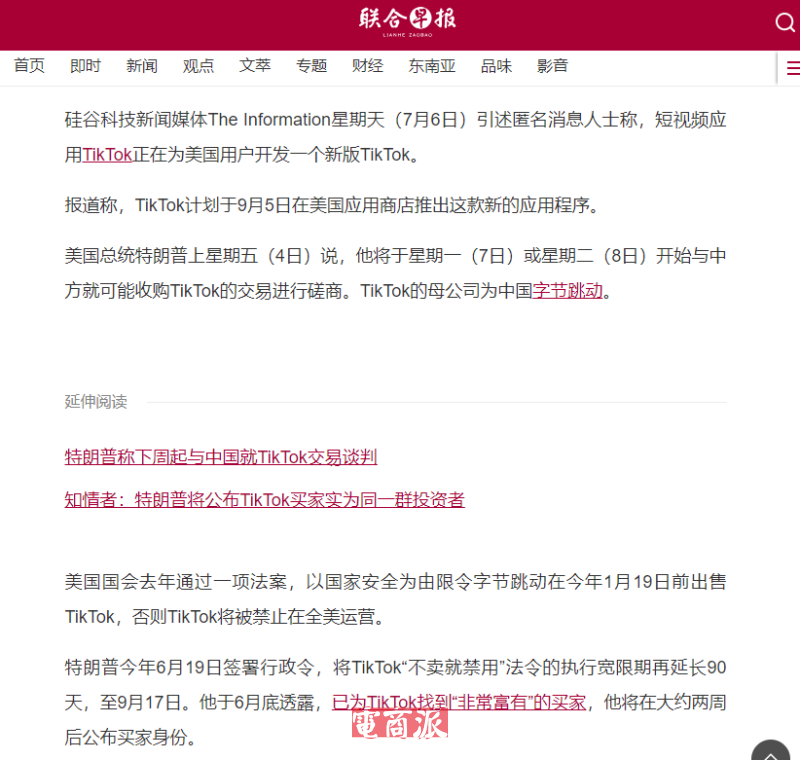
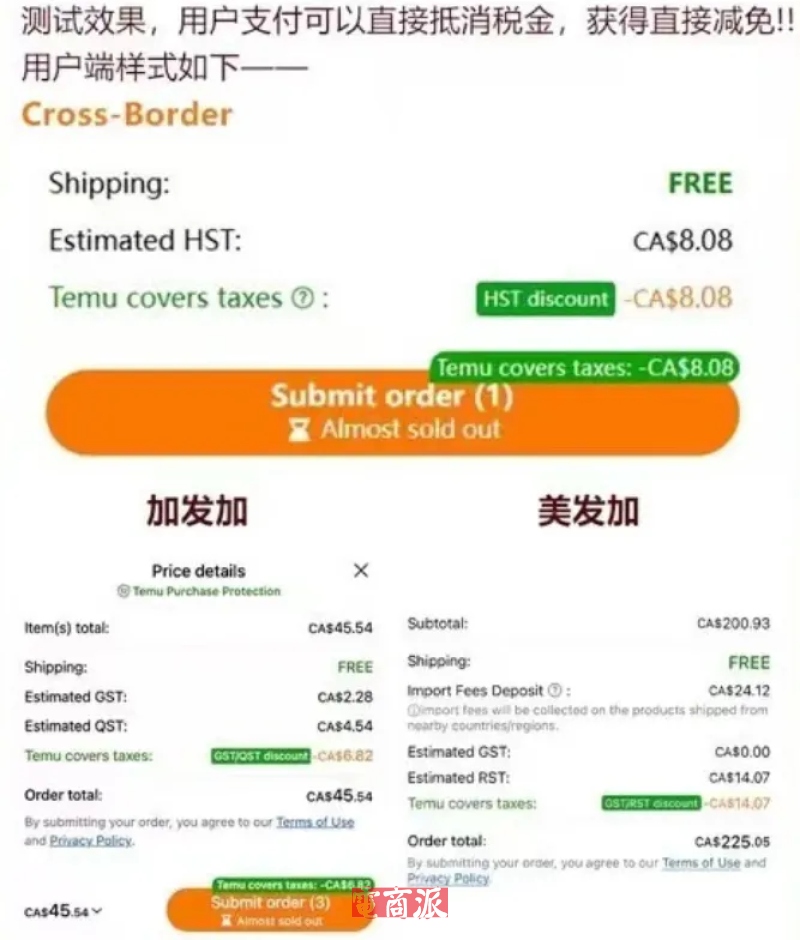
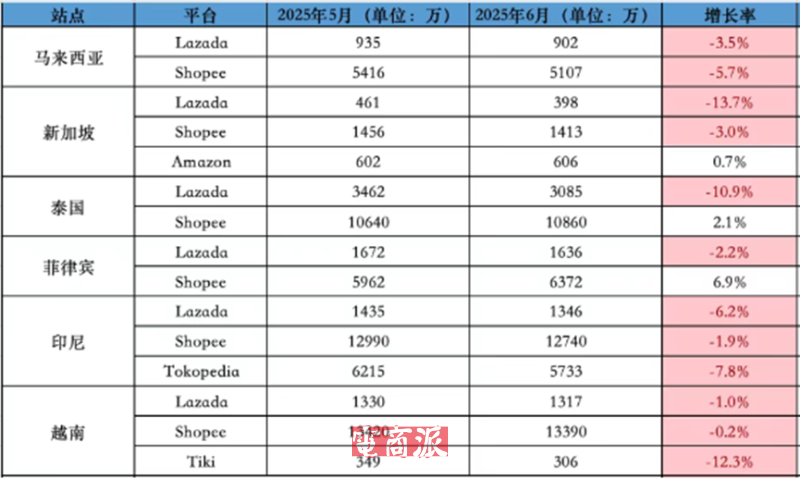
邮件群发-邮件群发软件|邮件批量发送工具|群发邮件平台|批量邮箱发送系统公司
邮件群发-邮件群发软件|邮件批量发送工具|群发邮件平台|批量邮箱发送系统公司htmlpath

`htmlpath` is not a widely known term in HTML programming. However
if you are referring to XPath
which is a language used for selecting nodes from an XML document
I can provide a brief explanation.
XPath stands for XML Path Language and is used to navigate through the elements and attributes of an XML document. It is often used in conjunction with HTML documents because they are based on the same markup language.
XPath uses expressions to select nodes or sets of nodes from an XML document. Here are some key concepts and syntax used in XPath:
1. Node selection: XPath uses different syntax to select different types of nodes. For example
to select all `
` elements
you would use the expression `//p`. The double forward slash (`//`) selects any `
` element in the document.
2. Predicates: Predicates are used to filter nodes based on certain conditions. For example
to select all `` elements with a `href` attribute containing the text "example.com"
you would use the expression `//a[contains(@href
'example.com')]`.
3. Axes: Axes are used to select nodes relative to a current node. Common axes in XPath include `ancestor`
`descendant`
`parent`
`child`
`preceding`
and `following`. For example
to select all `
` elements that are descendants of a `
` element with the class "container"
you would use the expression `//div[@class='container']//h2`.
4. Functions: XPath provides various functions for performing operations on nodes or values. Some common functions include `text()`
`count()`
`concat()`
and `substring()`. For example
to select the text of all `
` elements
you would use the expression `//p/text()`.
XPath expressions can be used in various programming languages and tools
such as JavaScript
PHP
Python
and XML editors. They are particularly useful for parsing XML or HTML documents and extracting specific data or elements.
In conclusion
XPath is a powerful language for navigating and selecting nodes in XML documents. Its syntax allows developers to target specific elements and attributes based on various conditions and relationships. By understanding and utilizing XPath
developers can efficiently work with XML or HTML data.
免责声明:本文内容由互联网用户自发贡献自行上传,本网站不拥有所有权,也不承认相关法律责任。如果您发现本社区中有涉嫌抄袭的内容,请发送邮件至:dm@cn86.cn进行举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。本站原创内容未经允许不得转载。
上一篇: 大一html网页制作作业简单
下一篇: css转less
you would use the expression `//div[@class='container']//h2`.
4. Functions: XPath provides various functions for performing operations on nodes or values. Some common functions include `text()`
`count()`
`concat()`
and `substring()`. For example
to select the text of all `
` elements
you would use the expression `//p/text()`.
XPath expressions can be used in various programming languages and tools
such as JavaScript
PHP
Python
and XML editors. They are particularly useful for parsing XML or HTML documents and extracting specific data or elements.
In conclusion
XPath is a powerful language for navigating and selecting nodes in XML documents. Its syntax allows developers to target specific elements and attributes based on various conditions and relationships. By understanding and utilizing XPath
developers can efficiently work with XML or HTML data.